Кейс
AI Onboarding Copilot
RAG-ассистент по внутренним знаниям компании: отвечает на вопросы новичков строго по документации из 3 платформ, со ссылками на источники и эскалацией при неуверенности.
Проблема
Знания размазаны, новички ждут
В SaaS-компаниях среднего размера знания для онбординга размазаны по нескольким платформам: Google Docs, Kaiten, Wiki, чаты и устные договорённости.
- 30–60 мин/день тимлид тратит на повторяющиеся вопросы от новичков
- 80% вопросов повторяются от одного новичка к другому
- 4–8 недель до продуктивности вместо возможных 2–3
- 1–3 часа среднее время ответа, потому что тимлид занят основной работой
- Нет аналитики — никто не знает, какие темы вызывают больше всего затруднений
Команды уже используют ChatGPT ad-hoc, но без guardrails: модель галлюцинирует политики, не ссылается на источники и не эскалирует то, чего не знает.
Решение
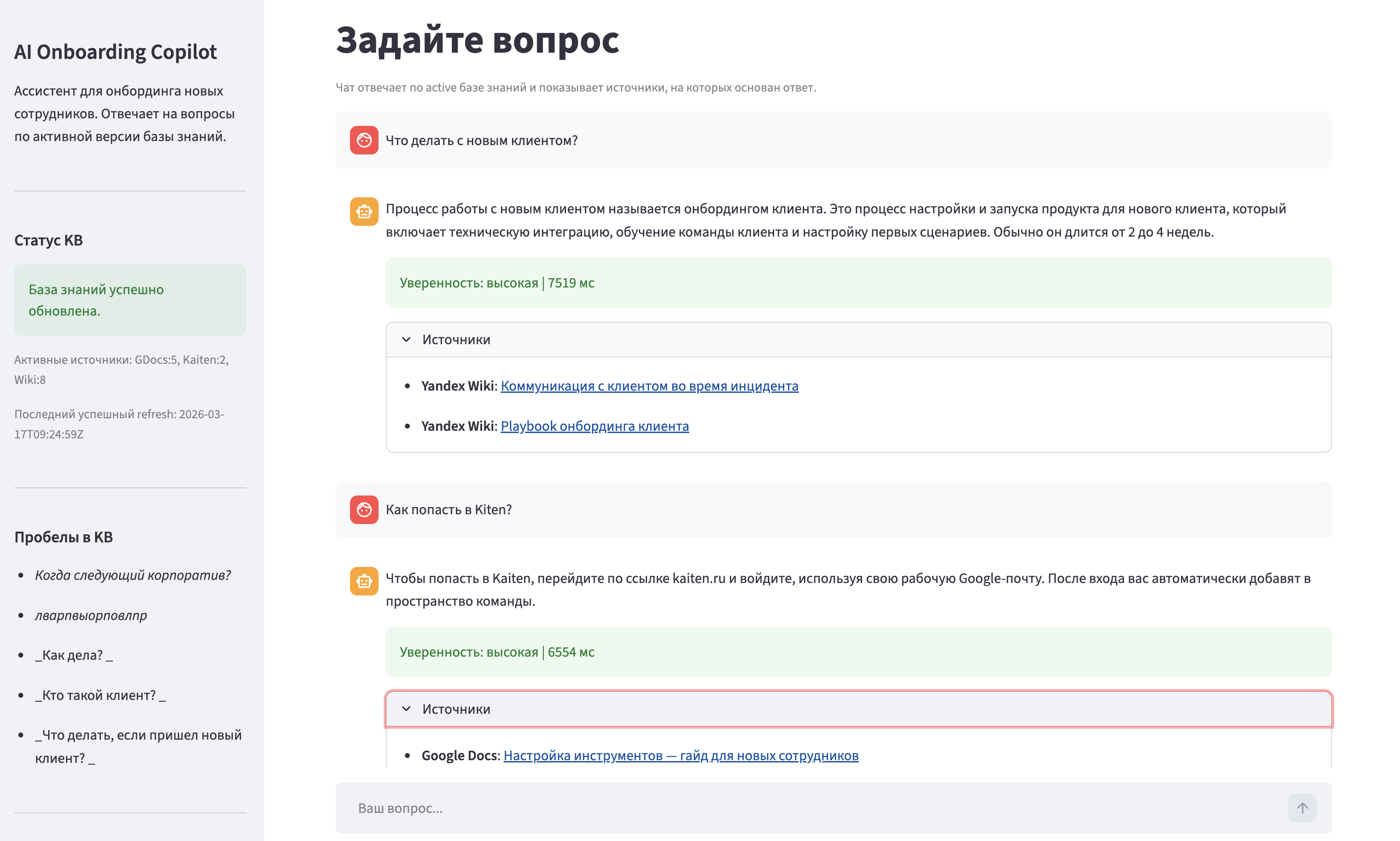
RAG-pipeline по 3 платформам
Ассистент отвечает на вопросы строго по внутренней документации. При low confidence эскалирует к тимлиду и записывает пробел в базу знаний.
Управление базой знаний
Администратор добавляет и удаляет источники через UI. Система автоматически переиндексирует документы при обновлении.
Ключевой принцип: human augmentation, not replacement. Копилот — first line для 70–80% вопросов, тимлид — second line для сложных.
Архитектурные решения
Почему именно такой стек
Почему 3 реальные платформы?
Multi-source RAG с инструментами российского рынка. Notion заблокирован в РФ, Confluence — с 2022. Каждая платформа — свой API, свой формат, нормализация в единую схему. Знания компании никогда не живут в одном месте.
Почему DeepSeek V3?
OpenAI API недоступен из России. DeepSeek доступен напрямую, хорошо работает на русском и остаётся OpenAI-compatible API, так что провайдера можно заменить без переписывания системы.
Почему Python, а не n8n?
RAG требует контроля над chunking, retrieval quality и evaluation. В n8n это неудобно и непрозрачно. Контент меняется в платформах без кода, промпт — в конфиг-файлах.
Почему низкий similarity threshold?
Для русскоязычных и mixed-language запросов retrieval давал более низкие scores. Лучше подтянуть больше контекста и отфильтровать на следующем шаге, чем агрессивно отсечь релевантный документ.
Результаты
Финальный evaluation на 87 вопросах
| Метрика | Результат | vs. baseline |
|---|---|---|
| Strict pass rate | 93.7% | vs 42% baseline |
| Answer quality rate | 98.7% | vs 46.4% baseline |
| Retrieval match rate | 94.9% | vs 68.1% baseline |
| Citation match rate | 93.7% | vs 62.3% baseline |
| Escalation accuracy | 100% | надёжный guardrail |
| Avg processing time | ~6 сек | vs 1–3 часа ожидание тимлида |
A/B-эксперимент
Embedding model: baseline vs multilingual
Чистый A/B: менялась только embedding model при неизменных источниках, промптах, eval set и retrieval thresholds.
| Метрика | all-MiniLM-L6-v2 | multilingual-MiniLM | Delta |
|---|---|---|---|
| Strict pass rate | 42.0% | 62.3% | +20.3 п.п. |
| Answer quality rate | 46.4% | 65.2% | +18.8 п.п. |
| Retrieval match rate | 68.1% | 76.8% | +8.7 п.п. |
| Citation match rate | 62.3% | 75.4% | +13.1 п.п. |
| Escalation accuracy | 58.4% | 72.7% | +14.3 п.п. |
| Avg processing time | 17759 ms | 7659 ms | −10100 ms |
Выводы
Что я понял
Качество retrieval определяет всё
Если правильный чанк не попал в top-k, никакой промпт не спасёт. Chunking strategy и embedding model влияют сильнее, чем выбор LLM.
Multi-source — самая трудоёмкая часть
Каждая платформа — свой API, свой формат, свои edge cases. Нормализация данных в единую схему — основная работа. Но именно это делает продукт ценным: пользователю не нужно знать, где хранится информация.
Без eval set улучшения — гадание
87 тестовых вопросов, regression set и A/B по embeddings позволили не только увидеть прирост, но и локализовать проблемные зоны: сначала glossary, потом wiki_*, затем source attribution.
PRD до кода — не формальность
Определение guardrails, escalation rules и success metrics до реализации предотвратило scope creep. AI-продукты требуют explicit constraints больше, чем классические фичи.
Хотите обсудить проект?
Расскажу подробнее про RAG-архитектуру, evaluation framework или любой другой аспект проекта.